Part 1. Why Arbitration Needs an Open Infrastructure Layer
By Lucas De Ferrari

What is this? Really, another article about AI? Yes.
In case you have been living under a rock, two things happened last month:
"Sullivan & Cromwell, a premier Wall Street law firm, apologized to a federal judge for submitting a court filing with inaccurate citations and other errors generated by artificial intelligence" (Reuters); and
"A Canadian court has annulled an award after finding the arbitrator improperly delegated his decision-making function to artificial intelligence, as his ruling was based on non-existent legal references" (GAR).
This is fascinating.
First, because it shows that everyone is using AI, probably all the time (assuming, reasonably, that these incidents are only the tip of the iceberg). Second, because it shows that people are, at least sometimes, using AI horribly wrong, in a way that betrays a lack of trust in the technology. And third, because in both cases the problem stemmed from hallucinated citations and references, which are central to legal submissions.
My own frustration with references and footnotes, and the inability to manage them reliably with AI, is what led me to develop AI-Native Arbitration Markup Language (AAML) for the recent GAR-LCIA Arbitration Hackathon.
AAML is a free and open markup standard for international arbitration submissions. In simple terms, it is an attempt to build something like HTML for arbitration documents: a shared, structured language that humans can read and that AI can process natively.
Note: This is Part 1 of a three-part series. Part 1 describes the current state of AI in international arbitration (I), and sets out the AAML standard and case for why it should be open (II). Part 2 explains how to use the standard, with examples of tested practical applications. Part 3 turns to implementation: the governance layer, and what adoption could look like for institutions and practitioners.
I - AI and International Arbitration
Even though AI is already widely used, there is far more that it theoretically could do - and probably soon will - in arbitration and many other fields (see this interesting Anthropic study):
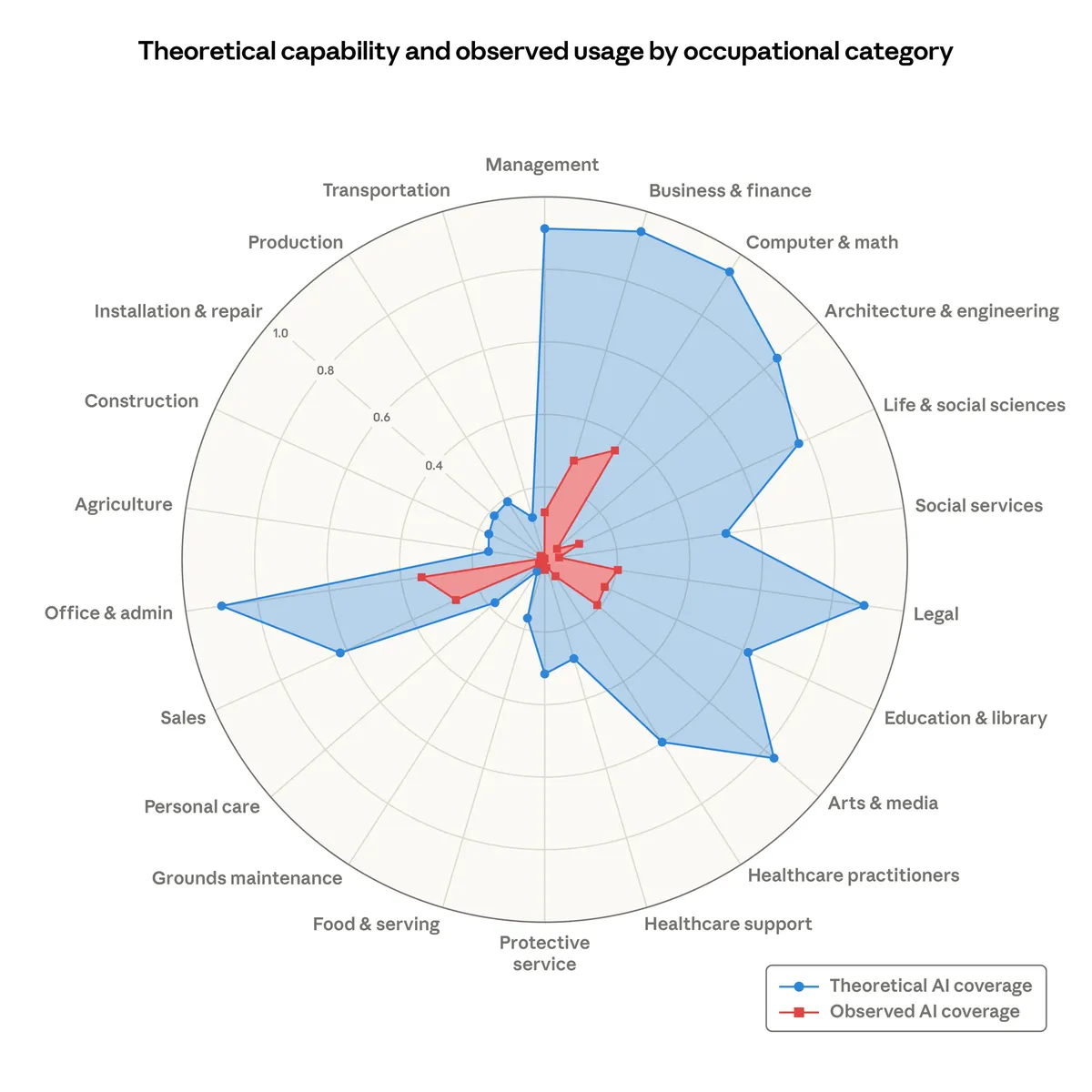
It is worth stressing how good frontier large language models (LLMs) have become. On certain hard tasks they are surprisingly effective: they make you feel faster, as if you can do more.
But the technology also has fundamental, hard-to-ignore limitations. The constant risk of hallucination is the main one, as last month's examples show. There is something poetic and very frustrating about a machine that instantly produces precise, well-written, intelligent text, with the minor caveat that it may all be completely wrong.
AI also struggles with complex tasks. Asking an AI to "conduct an arbitration" is pointless: today's LLMs cannot handle the scale and organizational demands of something that large. Working with AI therefore means constantly breaking big, complex projects into smaller discrete tasks, which is not how humans naturally work.
More fundamentally, people are not comfortable handing control to AI, and legitimately want to decide how and when it is used. What seems clear is that, for now, arbitration users are not willing to have their disputes decided by what is essentially a glorified autocomplete.
Part of the problem is that the way we work today simply isn't built for AI. Information lives in disparate systems: emails, shared drives, document management systems. That works when information is processed only by humans. It works poorly with AI.
II - AAML
AAML is intended to remove this friction by providing a common layer. The goal is to make the IT systems used in international arbitration speak the same language, let information flow freely between them, and keep all of it transparent, legible and auditable by humans:

Technically, AAML is a markup language - a system for organizing the formatting and content of documents. It rests on three principles.
1. Human control
Humans should remain in control of the arbitration process and own whatever they submit, regardless of whether AI (or any other tool) helped produce it.
AAML achieves this by being built primarily for humans, and by ensuring that all AI-generated work can be accessed and reviewed by humans at every stage of the process.
AAML is based on Markdown, the lightweight markup language created by John Gruber and Aaron Swartz in 2004 to make formatting text on the web as natural as taking notes. Markdown's design philosophy is simplicity: a few conventions (**bold**, *italic*, # headings) handle the vast majority of formatting needs without ever leaving the keyboard. Twenty years on, it has become the lingua franca of modern documentation, read and written natively by an enormous range of systems, including, crucially, every major LLM (more on this below). And its feature set (six heading levels, bold, italics, block quotes, etc.) is more than enough to draft detailed arbitration submissions, procedural orders, or any similar document.
AAML inherits all of that. The full syntax can be learned in fifteen minutes, far less than even the basics of word-processing software, with its advanced formatting, styles, footnotes and cross-references (all with a strange tendency to break at 3AM on filing day).
2. AI-Native
Markdown is also fully native to AI: models learned the language from their training data. Every LLM (whether running on generalist tools like ChatGPT / Claude, or specialized legal platforms like Legora / Mike OSS) can output Markdown natively and reliably. That makes it the ideal candidate for standardization.
It is also very lightweight (for the same text, a Markdown file is roughly 20x smaller than a PDF) and lends itself to processing, particularly chunking (the breaking of long documents into smaller pieces that fit more easily into an LLM's context window).
But Markdown alone cannot handle legal submissions, which are complex in both citation and structure.
AAML therefore adds a symbolic reference syntax: citations are written inline using simple identifiers, like [[contract|cl. 8.3, p. 7]] or [[ex:delay-notice]], instead of manually typed exhibit numbers and footnotes. This separates authoring from production: the lawyer (or the AI) writes prose with semantic references, and a production engine handles the rest at render time, assigning exhibit numbers, generating footnotes, populating the exhibit list, and producing the final PDF or Word output.
Exhibits themselves need only minimal processing: simple metadata in a short YAML header (title, date, type, party, alias). Citations stay inline throughout drafting, which is far easier for LLMs to process.
3. Free and Open Standard
Why does this need to be a standard at all? Strictly, it doesn't. The gap between what AI can do and what it actually does in arbitration will close one way or another, and tools to bridge it will get built.
Neutrality is one of the foundations of international arbitration's legitimacy, and as AI capabilities grow, that same logic should extend to the infrastructure layer on which AI-assisted arbitrations will run. If the system that defines how submissions, exhibits and citations are structured is proprietary, then whoever owns it holds leverage over how disputes are conducted. That infrastructure is simply better off as an open standard.
The second reason is more practical, and the GAR-LCIA organizers identified it themselves. As Hugh Carlson and Megan Ma observed in their excellent write-up of the hackathon, international arbitration is a comparatively small market: public data is scarce, volumes are dwarfed by US commercial litigation and M&A due diligence, and capital has not, until very recently, prioritized the field. An open standard lowers the cost of building anything useful, because each new tool can assume a shared substrate. A drafting assistant, an exhibit manager and a verification engine built by three different developers all become more valuable the moment they speak the same language.
Finally, arbitration is a particularly good candidate for this kind of standardization. Because it is consent-based, transnational, and operates outside any single state, the arbitration community has long organized itself through practice, soft law and consensus. AAML fits naturally into that tradition.
Part 2 explains how AAML can be used, in practice, with application examples (tested in real life conditions).
If you want to know more, the standard is available for download and testing here.